JavaScript 算法

介绍
传统的 面试过程 通常以最基本的如何编写 手机屏幕页面 问题为开始,然后通过全天的 现场工作 来检验 编码能力 和 文化契合 度。 几乎无一例外,决定性的因素还是 编码能力。 毕竟,工程师是靠一天结束之时产出可使用的软件来获得报酬的。一般来说,我们会使用 _白板_ 来测试这种编码能力。比获得正确答案更重要的是清晰明了的思考过程。编码和生活一样,正确的答案不总是显而易见的,但是好的论据通常是足够好的。 _有效_ 的 _推理_ 能力标志着学习,适应和发展的潜力。最好的工程师总是在成长,最好的公司总是在不断创新。
算法挑战 是有效的锻炼能力的方法,因为总有不止一种的方法来解决它们。这为决策和演算决策提供了可能性。当解决算法问题的时候,我们应该挑战自我,从多个角度来看 问题的定义 ,然后权衡各种方式的 _益处_ 和 _缺陷_ 。通过足够的联系,我们甚至可以一瞥宇宙的真理; 没有“完美”的解决方案 。
真正掌握 算法 就是去理解 数据 和 结构 之间的关系。数据结构和算法之间的关系,就如同“阴”之于“阳”, 玻璃杯 之于 _水_ 。没有玻璃杯,水就无法被承载。没有数据结构,我们就没有可以用于逻辑的对象。没有水,玻璃杯会因为缺乏物质而变空。没有算法,对象就无法被转化或者“消费”。
关于数据结构深入分析,可以参考: Data Structures in JavaScript_:_
引言
应用于代码中,一个算法只是一个把确定的 数据结构 的 输入 转化为一个确定的 数据结构 的 输出 的 function 。算法 _内在_ 的 逻辑 决定了如何转换。首先,输入和输出应该被 _明确_ 定义为 单元测试。这需要完全的理解手头的问题,这是不容小觑的,因为彻底分析问题可以无需编写任何代码,就自然地解决问题。
一旦彻底掌握问题的领域,就可以开始对解决方案进行 头脑风暴 。 需要哪些变量?需要多少循环以及哪些类型的循环?有没有巧妙的内置的方法可以提供帮助?需要考虑哪些边缘情况? 复杂和重复的逻辑只会徒增阅读和理解的难度。 帮助函数可以被抽象或者抽离吗? 算法通常需要是可扩展的。 随着输入规模的增加,函数将如何执行? 是否应该有某种缓存机制? 而性能优化(时间)通常需要牺牲内存空间(增加内存消耗)。
为了使问题更具体,让我们来绘制一个 图表 !
当解决方案中的高级结构开始出现时,我们就可以开始写 伪代码 了。为了给面试官留下真正的印象,
请 _优先_ 考虑代码的重构和 复用 。有时,行为类似的函数可以合并成一个可以接受额外参数的更通用的函数。其他时候,去参数化会更好。保持函数的 纯净 以便于测试和维护也是很有先见之明的。换言之,设计算法时,将 架构 和 设计模式 纳入到你的考虑范围内。
如果有任何不清楚的地方,请 _提问_ 以便说明!
Big O(算法的复杂度)
为了估算算法运行时的复杂度,在计算算法所需的 操作次数 之前,我们通常把 输入大小 外推至无穷来估算算法的可扩展性。在这种最坏情况的运行时上限情况下,我们可以忽略系数以及附加项,只保留主导函数的因子。因此,只需要几种类型就可以描述几乎所有的可扩展算法。
最优最理想的算法,是在时间和空间维度以 _常数_ 速率变化。这就是说它完全不关心输入大小的变化。次优的算法是对时间或空间以 _对数_ 速率变化,再次分别是 _线性_ , 线性对数 , _二次_ 和 _指数_ 型。最糟糕的是对时间或空间以 _阶乘_ 速率变化。在 Big-O 表示法中:
- 常数: O(1)
- 对数: O(log n)
- 线性: O(n)
- 线性对数: O(n log n)
- 二次: O(n²)
- 指数: O(2^n)
- 阶乘: O(n!)
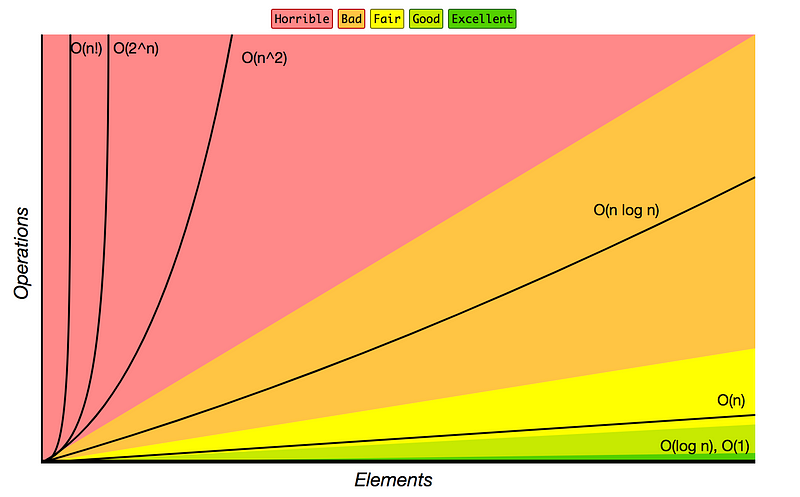
当我们考虑算法的时间和空间复杂性之间的权衡时,Big-O 渐近分析 是不可或缺的工具。然而,Big O 忽略了在实际实践中可能有影响的常量因素。此外,优化算法的时间和空间复杂性可能会增加现实的开发时间或对代码可读性产生负面影响。在设计算法的结构和逻辑时,对真正可忽略不计的东西的直觉同样重要。
Arrays(数组)
最干净的算法通常会利用语言中固有的 _标准_ 对象。可以说计算机科学中最重要的是Arrays。在JavaScript中,没有其他对象比数组拥有更多的实用工具方法。值得记住的数组方法是: sort, reverse, slice, 以及 splice。数组从 第0个索引 开始插入数组元素。这意味着最后一个数组元素的位置是 array.length — 1。数组是 _索引_ (推入) 的最佳选择,但对于 _插入_, _删除_ (不弹出), 和 _搜索_ 等动作非常糟糕。在 JavaScript 中, 数组可以 _动态_ 增长。
对应的 Big O :
- 索引: O(1)
- 插入: O(n)
- 删除: O(n)
- 暴力搜索: O(n)
- 优化搜索: O(log n)
这些 Array 方法在代码中的示例:
See the Pen
Arrays in JavaScript by Thon Ly (@thonly)
on CodePen.
完整的阅读 MDN 有关 Arrays 的文档也是值得的。
类似数组的还有 Sets 和 Maps. 在 set 中,元素一定是 _唯一_ 的。在 map 中,元素由字典式关系的 _键_ 和 _值_ 组成。当然,Objects (and their literals) 也可以储存键值对,但键必须是 strings 类型。
Object Object构造函数创建一个对象包装器
developer.mozilla.org
迭代
与 Arrays 密切相关的是使用循环 遍历 它们。在 JavaScript 中,我们可以用 _五种_ 不同的 控制结构 来迭代。可定制化程度最高的是 for 循环,我们几乎可以用它以任何顺序来遍历数组 _索引_ 。如果无法确定 迭代次数 ,我们可以使用 while 和 do while 循环,直到遇到一个满足确定条件的情况。对于任何对象,我们可以使用 for in 和 for of 循环来分别迭代它的“键”和“值”。要同时获取“键”和“值”,我们可以使用它的 entries() 方法。我们可以通过 break语句随时 中断循环 break, 或者使用 continue 语句 _跳到_ 。在大多数情况下,通过 generator 函数来控制迭代是最好的选择。
原生的遍历所有数组项的方法是: indexOf, lastIndexOf, includes, fill 和 join。 另外,我们可以为以下方法提供 回调函数 : findIndex, find, filter, forEach, map, some, every 和 reduce。
这些 Array 方法在代码中的示例:
See the Pen
Objects in JavaScript by Thon Ly (@thonly)
on CodePen.
递归
在一篇开创性的论文 Church-Turing Thesis 中,证明了任何迭代函数都可以用递归函数重写,反之亦然。有时,递归方法更简洁,更清晰,更优雅。就用这个 factorial 阶乘迭代函数来举例:
1 | const **factorial** = number => { |
用 recursive 递归函数来写,只需要 _一行_ 代码!
1 | const **factorial** = number => { |
所有递归函数都有一个 通用模式 。它们总是由一个调用自身的 递归部分 和一个不调用自身的 基本情形 组成。当一个函数调用自己的时候,它就会将一个新的 执行上下文 推送到 执行堆栈 里。这种情况会一直持续进行下去,直到遇到 基本情形 ,然后 _堆栈_ 逐个弹出展开成 各个上下文。因此,草率的依赖递归会导致可怕的运行时 堆栈溢出 错误。
factorial 阶乘函数的代码示例:
See the Pen
Factorial in JavaScript by Thon Ly (@thonly)
on CodePen.
终于,我们准备好接受任何算法挑战了!😉
热门的算法问题
在本节中,我们将按照难度顺序浏览22个 经常被问到的 算法问题。我们将讨论不同的方法和它们的利弊以及运行中的时间复杂性。最优雅的解决方案通常会利用特殊的 “技巧” 或者敏锐的洞察力。记住这一点,让我们开始吧!
1. 反转字符串
把一个给定的 一串字符 当作 _输入_ ,编写一个函数,将传入字符串 _反转_ 字符顺序后返回。
1 | describe("String Reversal", () => { |
分析:
如果我们知道“技巧”,那么解决方案就不重要了。技巧就是意识到我们可以使用 _数组_ 的内置方法 reverse 。首先,我们对 字符串 使用 split 方法生成一个 字符数组 ,然后我们可以用 reverse 方法,最后用 join 方法将字符数组重新组合回一个 字符串。这个解决方案可以用一行代码来完成!虽然不那么优雅,但也可以借助最新的语法和帮助函数来解决问题。使用新的 for of 循环迭代字符串中的每一个字符,可以展示出我们对最新语法的熟悉情况。或者,我们可以用数组的 reduce 方法,它使我们不再需要保留临时基元。
对于给定的字符串的每个字符都要被“访问”一次。虽然这中访问会多次发生,但是 _时间_ 可以被归一化为 _线性_ 时间。并且因为没有单独的内部状态需要被保存,因此 _空间_ 是 _恒定_ 的。
代码:
See the Pen
String Reversal in JavaScript by Thon Ly (@thonly)
on CodePen.
2. 回文
_回文_ 是指一个 单词 或 短语 正向和反向 阅读都是一样的。写一个函数来验证给定输入值是否是回文。
1 | describe("Palindrome", () => { |
分析:
这里的关键点是意识到:我们基于在前一个问题中学到的东西来解决。除此之外,我们需要返回一个 布尔 值。这就像对 原始字符串 返回 三重等式 检查一样简单。我们还可以在 _数组_ 上使用新的 every 方法来检查 第一个 和 最后一个 字符是否按顺序 以中心为对称点 匹配。然而,这会使检查次数超过必要次数的两倍。与前一个问题类似,这个问题的时间和空间的运行时复杂性都 是相同的。
如果我们想扩展我们的功能以测试整个 _短语_ 怎么办?我们可以创造一个 帮助函数 ,它对 字符串 使用 正则表达式 和 replace 方法来剔除非字母字符。如果不允许使用正则表达式,我们就创造一个由 可接受字符 组成的 数组 用作过滤器。
代码:
See the Pen
Palindrome in JavaScript by Thon Ly (@thonly)
on CodePen.
3. 整数反转
给定一个 整数, _反转_ 数字的顺序。
1 | describe("Integer Reversal", () => { |
分析:
这里的技巧是先把数字通过内置的 toString 方法转化为一个 字符串 。然后,我们可以简单的复用 反转字符串 的算法逻辑。在数字反转之后,我们可以使用全局的 parseInt 函数将字符串转换回整数,并使用 Math.sign 来处理数字的符号。这种方法可以简化为一行代码!
由于我们复用了 反转字符串 的算法逻辑,这个算法的时间和空间的运行时复杂度也与之前相同。
代码:
See the Pen
Integer Reversal by Thon Ly (@thonly)
on CodePen.
4. Fizz Buzz
给定一个 数字 作为输入值, 打印出从 1 到给定数字的所有整数。 但是,当整数可以被 2 整除时,打印出“Fizz”; 当它可以被3整除时,打印出“Buzz”; 当它可以同时被2和3整除时,打印出“Fizz Buzz”。
1 | describe("Fizz Buzz", () => { |
分析:
当我们意识到 模运算符 可用于检查可分性(是否能被整除)时,这个经典算法的挑战就变得非常简单了。模运算符对两个数字求余,返回两数相除的余数。因此我们可以简单的遍历每个整数,检查它们对2、3整除的余数是否等于 0。这展现了我们的数学功底,因为我们知道当一个数可以同时被 a 和 b整除时,它也可以被它们的 最小公倍数 整除。
同样,这个算法的时间和空间的运行时复杂度也与之前相同,因为每一个整数都被访问和检查过一次但不需要保存内部状态。
代码:
See the Pen
Fizz Buzz in JavaScript by Thon Ly (@thonly)
on CodePen.
5. 最常见字符
给定一个由字符组成的 字符串,返回字符串中 出现频次最高 的 字符 。
1 | describe("Max Character", () => { |
分析:
这里的技巧是创建一个表格,用来记录遍历字符串时每个字符出现的次数。这个表格可以用 对象字面量 来创建,用 字符 作为对象字面量的 _键_ ,用字符出现的 次数 作为 _值_ 。然后,我们遍历表格,通过一个保存每个键值对的 _临时_ 变量 来找到出现频次最大的字符。
虽然我们使用了两个独立的循环来遍历两个不同的输入值( 字符串 和 字符映射 ),但时间复杂度仍然是 _线性_ 的。虽然循环是对于字符串,但最终,字符映射的大小会有一个极限,因为任何一种语言的字符都是 _有限_ 个的。出于同样的原因,虽然要保存内部状态,但不管输入字符串如何增长,空间复杂度也是 _恒定_ 的。临时基元在大尺度上看也是可以忽略不计的。
代码:
See the Pen
Max Character by Thon Ly (@thonly)
on CodePen.
6. Anagrams
Anagrams是包含 相同字符 的 单词 或 短语 。写一个检查此功能的 函数。
1 | describe("Anagrams", () => { |
分析:
一种显而易见的方法是创建一个 字符映射 ,该映射计算每个输入字符串的字符数。之后,我们可以比较映射来看他们是否相同。创建字符映射的逻辑可以抽离成一个 帮助函数 从而更方便的复用。为了更缜密,我们应该首先把字符串中所有非字符删掉,然后把剩下的字符变成小写。
正如我们所见,字符映射具有 _线性_ 时间复杂度和 _恒定_ 的空间复杂度。更确切地说,这种方法对于时间具有 O(n + m) 复杂度,因为检查了两个不同的字符串。
另一种更优雅的方法是我们可以简单的对输入值 排序 ,然后检查它们是否相等!然而,它的缺点是排序通常需要 _线性_ 时间。
代码:
See the Pen
Anagrams by Thon Ly (@thonly)
on CodePen.
7. 元音
给定一个 字符串 类型的单词或短语, _计算_ 元音 的个数.
1 | describe("Vowels", () => { |
分析:
最简单的办法是使用 正则表达式 取出所有的元音字母,然后计算它们的数量。如果不允许使用正则表达式,我们可以简单的遍历每一个字符,检查它是否是原因字母。不过首先要把字符串转化为 _小写_ 。
两种方法都是 _线性_ 时间复杂度和 _恒定_ 空间复杂度,因为每一个字符都需要被检查一次,而临时基元可以忽略不计。
代码:
See the Pen
Vowels by Thon Ly (@thonly)
on CodePen.
8. 数组块
对于一个给定 大小 的 数组 ,将数组 _元素_ 分割成一个给定大小的 _数组_ 类型的 列表 。
1 | describe("Array Chunking", () => { |
分析:
一个显而易见的方法是保持一个对最后一个“块”的引用,并在遍历数组元素时检查其大小来判断是否应该向最后一个块中放元素。更优雅的解决方案是使用内置的 slice 方法。这样就不需要“引用”,从而使代码更清晰。这可以通过 while 循环或 for 循环来实现,该循环以给定大小的step递增。
这些算法都具有 _线性_ 时间复杂度,因为每个数组项都需要被访问一次。它们也都有 _线性_ 的空间复杂度,因为需要保存一个内在的 “块” 类型数组,该数组大小会随着输入值变化而变化。
代码:
See the Pen
Array Chunking by Thon Ly (@thonly)
on CodePen.
9. 反转数组
给定一个任意类型的 数组 , _反转_ 数组的顺序。
1 | describe("Reverse Arrays", () => { |
分析:
当然最简单的解决办法是使用内置的 reverse 方法。但这也太赖皮了!如果不允许使用这种方法,我们可以简单循环数组的一般,并 _交换_ 数组的开头和结尾的元素。这意味着我们要在内存里暂存 _一个_ 数组元素。为了避免这种对暂存的需要,我们可以对数组对称位置的元素使用 结构赋值 。
虽然只遍历了输入数组的一半,但时间复杂度仍然是 _线性_ 的,因为 Big O 近似地忽略了系数。
代码:
See the Pen
Reverse Arrays in JavaScript by Thon Ly (@thonly)
on CodePen.
10. 反转单词
给定一个 词组, _反转_ 词组中每个单词的字符顺序。
1 | describe("Reverse Words", () => { |
分析:
我们可以使用split方法创建单个单词的数组。然后对每一个单词,我们使用 反转字符串 的逻辑来反转它的字符。另一种方法是 _反向_ 遍历每个单词,并将结果存储在临时变量中。无论哪种方式,我们都需要暂存所有反转的单词,最后再把它们拼接起来。
由于每一个字符都被遍历了一遍,并且所需的临时变量大小与输入字符串成比例,所以时间和空间复杂度都是 _线性_ 的。
代码:
See the Pen
Reverse Words in JavaScript by Thon Ly (@thonly)
on CodePen.
11. 首字母大写转换
给定一个 词组,对每一个单词进行 首字母大写 。
1 | describe("Capitalization", () => { |
分析:
一种解决方法是遍历每个字符,当遍历字符的前一个字符是 _空格_ 时,就对当前字符使用 toUpperCase 方法使其变成大写。由于 字符串文字 在 JavaScript 中是 不可变 的,所以我们需要使用适当的大写转化方法重建输入字符串。这种方法要求我们始终将第一个字符大写。另一种更简洁的方法是将输入字符串 split 成一个 由单词组成的数组 。然后,遍历这个数组,将每个元素第一个字符大写,最后将单词重新连接在一起。出于相同的不可变原因,我们需要在内存里保存一个 临时数组 来保存被正确大写的单词。
两种方式都是 _线性_ 的时间复杂度,因为每个字符串都被遍历了一次。它们也都是 _线性_ 的空间复杂度,因为保存了一个临时变量,该变量与输入字符串成比例增长。
代码:
See the Pen
Capitalization by Thon Ly (@thonly)
on CodePen.
12. 恺撒密码
给定一个 短语, 通过将每个字符 _替换_ 成字母表向前或向后移动一个给定的 整数 的新字符。如有必要,移位应绕回字母表的开头或结尾。
1 | describe("Caesar Cipher", () => { |
分析:
首先,我们需要创建一个 字母表字符 组成的 数组 ,以便计算移动字符的结果。这意味着我们要在遍历字符之前先把 输入字符串 转化为小写。我们很容易用常规的 for 循环来跟踪当前索引。我们需要构建一个包含每次迭代移位后的字符的 新字符串 。注意,当我们遇到非字母字符时,应该立即将它追加到我们的结果字符串的末尾,并使用 continue 语句跳到下一次迭代。有一个关键点事要意识到我们可以使用 模运算符 模拟当移位超过26时,循环计数到字母表数组的开头或结尾的行为。最后,我们需要在将结果追加到结果字符串之前检查原始字符串中的大小写。
由于需要访问每一个输入字符串的字符,并且需要根据输入字符串新建一个结果字符串,因此这个算法的时间和空间复杂度都是 _线性_ 的。
代码:
See the Pen
Caesar Cipher in JavaScript by Thon Ly (@thonly)
on CodePen.
13. Ransom Note
给定一个 magazine段落 和一个 ransom段落,判断 magazine段落 中是否包含每一个 ransom段落 中的单词 。
const magazine =
“Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum“;
1 | describe("Ransom Note", () => { |
分析:
显而易见的做法是把magazine段落和ransom段落分拆成由单个单词组成的 _数组_ ,然后检查每个ransom单词是否存在于magazine段落中。然而,这种方法的时间复杂度是 _二次_ 的,或者说是 O(n * m) 的,这说明这种方法性能不好。如果我们首先创建一个magazine段落的单词表格,然后检查ansom段落中的每个词是否存在于这张表格中,我们就可以实现 _线性_ 时间复杂度。这是因为在 映射对象 中的查找总是可以在 _恒定_ 时间内完成。但是我们将会牺牲空间复杂度,因为需要把映射对象保存在内存里。
在代码中,这意味着我们需要创建每个magazine段落中单词的计数,然后检查 “hash 表格” 是否包含正确数量的ransom单词。
代码:
See the Pen
Ransom Note in JavaScript by Thon Ly (@thonly)
on CodePen.
14. 平均值,中位数和Mode(出现次数最多的数字)
给定一个数字组成的 数组 ,计算这些数的 平均值 , 中位数 和 Mode 。
1 | const **stat1** = new Stats(\[1, 2, 3, 4, 4, 5, 5\]); |
分析:
从难度方面讲,找到数字集合 平均值 的算法是最简单的。统计学上, 平均值 的定义是数字集合的 _和_ 除以数字集合的 _数量_ 。因此,我们可以简单的使用数组的 reduce 方法来对它求和,然后除以它的 长度。这个算法的运行时复杂度对时间是 _线性_ 的,对空间是 _恒定_ 的。因为每一个数字在遍历的过程中都需要被求和但不需要在内存里保存变量。
找到集合 中位数 的算法困难度是中等的。首先,我们需要给数组排序,但如果集合的长度是基数,我们就需要额外的逻辑来处理中间的两个数字。这种情况下,我们需要返回这两个数字的 平均值 。这个算法因为需要排序,所以具有 线性对数 时间复杂度,同时因为需要内存来保持排序的数组,所以具有 _线性_ 的空间复杂度。
找到 mode 的算法是最为复杂的。由于 mode 被定义为最常出现的一个或多个数字,我们需要在内存中维护一个 频率表 。更复杂的是,如果每个值出现的次数都相同,则没有mode。这意味着在代码中,我们需要创建一个 哈希映射 来计算每一个“数”出现的频率;然后遍历这个映射来找到最高频的一个或多个数字,当然也可能没有mode。因为每个数字都需要在内存中保留和计数,所以这个算法具有 _线性_ 的时间和空间复杂度。
代码:
See the Pen
Mean, Median, Mode in JavaScript by Thon Ly (@thonly)
on CodePen.
15. 多重求和
给定一组数字,返回满足“两数字之和等于给定 和 ”的 所有组合 。每个数字可以被使用不止一次。
1 | describe("Two Sum", () => { |
分析:
显而易见的解决方案是创建 嵌套循环 ,该循环检查每一个数字与同组中其他数字。那些满足求和之后满足给定和的组合可以被推入到一个 结果数组 中。然而,这种嵌套会引起 _指数_ 型的时间复杂度,这对于大输入值而言非常不适用。
一个讨巧的办法是在我们遍历输入数组时维护一个包含每个数字的 “对应物” 的数组,同时检查每个数字的对应物是否已经存在。通过维护这样的数组,我们牺牲了空间效率来获得 _线性_ 的时间复杂度。
代码:
See the Pen
Two Sum in JavaScript by Thon Ly (@thonly)
on CodePen.
16. 利润最大化
给定一组按照时间顺序给出的股票价格,找到 _最低_ 买入价 和 _最高_ 卖出价 使得 利润最大化 。
1 | describe("Max Profit", () => { |
分析:
同样,我们可以构建 嵌套循环 ,该循环检查买入价和卖出价的每种可能组合,看看哪一对产生最大的利润。实际操作中我们不能在购买之前出售,所以不是每个组合都需要被检查。具体而言,对于给定的买入价格,我们可以忽略卖出价格之前的所有价格。因此,该算法的时间复杂度优于 _二次_ 型。
不过稍微考虑一下,我们可以对价格数组只使用一次循环来解决问题。关键点是要意识到卖价绝不应低于买入价; 如果是这样,我们应该以较低的价格购买股票。就是说在代码中,我们可以简单的维护一个 临时布尔值 来表示我们应该在下一次迭代时更改买入价格。这种优雅的方法只需要一个循环,因此具有 _线性_ 的时间复杂度和 _恒定_ 的空间复杂度。
代码:
See the Pen
Max Profit in JavaScript by Thon Ly (@thonly)
on CodePen.
17. Sieve of Eratosthenes
对于给定的 数字 ,找到从零到该数字之间的所有 _素数_ 。
1 | describe("Sieve of Eratosthenes", () => { |
分析:
乍一看,我们可能想要遍历每个数字,只需使用模数运算符来检查所有可能的可分性。然而,很容易想到这种方法非常低效,时间复杂度比二次型还差。值得庆幸的是,地理学的发明者 Eratosthenes of Cyrene 还发现了一种有效的识别素数的方法。
在代码中,第一步是创建一个与给定数字一样大的数组,并将其每个元素初始化为 true 。换句话说,数组的 _索引_ 代表了所有可能的素数,并且每个数都被假定为 true 。然后我们建立一个 for 循环来遍历从 2 到给定数字的 平方根 之间的数,使用数组的 键插值 来把每个被遍历数的小于给定数的倍数对应的元素值设为 false 。根据定义,任何整数的乘积都不能是素数,这里忽略0和1,因为它们不会影响可分性。最后我们可以简单的筛掉所有 _假值_ ,以得出所有素数。
通过牺牲空间效率来维护一个内部的 “hash表”,这个Eratosthenes的 _筛子_ 在时间复杂度上会优于 _二次_ 型,或者说是 O(n * log (log n))。
代码:
See the Pen
Sieve of Eratosthenes in JavaScript by Thon Ly (@thonly)
on CodePen.
18. 斐波那契通项公式
实现一个返回给定 索引 处的 斐波纳契数 的 函数。
1 | describe("Fibonacci", () => { |
分析:
由于斐波纳契数是前两者的总和,最简单的方法就是使用 _递归_ 。斐波纳契数列假定前两项分别是1和1; 因此我们可以基于这个事实来创建我们的 基本情形 。对于索引大于2的情况,我们可以调用自身函数的前两项。虽然看着很优雅,这个递归方法的效率却非常糟糕,它具有 _指数_ 型的时间复杂度和 _线性_ 的空间复杂度。因为每个函数调用都需要调用堆栈,所以内存使用以指数级增长,如此一来它会很快就会崩溃。
迭代的方法虽然不那么优雅,但是时间复杂度却更优。通过循环,建立一个完整的斐波纳契数列前N项目(N为给定索引值),这可以达到 _线性_ 的时间和空间复杂度。
代码:
See the Pen
Fibonacci in JavaScript by Thon Ly (@thonly)
on CodePen.
19. Memoized Fibonacci
给斐波纳契数列实现一个 _高效_ 的递归函数。
1 | describe("Memoized Fibonacci", () => { |
分析:
由于斐波纳契数列对自己进行了冗余的调用,因此它可以戏剧性的从被称为 记忆化 的策略中获益匪浅。换句话说,如果我们在调用函数时 _缓存_ 所有的输入和输出值,则调用次数将减少到 _线性_ 时间。当然,这意味着我们牺牲了额外的内存。
在代码中,我们可以在函数本身内部实现 记忆化 技术,或者我们可以将它抽象为高阶效用函数,该函数可以装饰任何 记忆化 函数。
代码:
See the Pen
Memoized Fibonacci in JavaScript by Thon Ly (@thonly)
on CodePen.
20. 画楼梯
对于给定长度的 步幅 ,使用 _#_ and ‘ ’ 打印出一个 “楼梯” 。
1 | describe("Steps", () => { |
分析:
关键的见解是要意识到,当我们向下移动步幅时,# 的数量会不断 _增加_ ,而 ‘ ‘ 的数量会相应 _减少_ 。如果我们有 n 步要移动,全局的范围就是 n 行 n 列。这意味着运行时复杂度对于时间和空间都是 _二次_ 型的。
同样,我们发现这也可以使用递归的方式来解决。除此之外,我们需要传递 额外的参数 来代替必要的临时变量。
代码:
See the Pen
Staircase by Thon Ly (@thonly)
on CodePen.
21. 画金字塔
对于给定数量的 阶层 ,使用 _#_ 和 ‘ ‘ 打印出 “金字塔”。
1 | describe("Pyramid", () => { |
分析:
这里的关键时要意识到当金字塔的高度是 n 时,宽是 2 * n — 1。然后随着我们往底部画时,只需要以中心对称不断 _增加_ _#_ 的数量,同时相应 _减少_ ‘ ‘ 的数量。由于该算法以 2 * n - 1 * n 遍历构建出一个金字塔,因此它的运行时时间复杂度和空间复杂度都是 二次 型的。
同样,我们可以发现这里的递归调用可以使用之前的方法:需要传递一个 附加变量 来代替必要的临时变量。
代码:
See the Pen
Pyramid by Thon Ly (@thonly)
on CodePen.
22. 螺旋方阵
创建一个给定 大小 的 _方阵_ ,使方阵中的元素按照 螺旋顺序 排列。
1 | describe("Matrix Spiral", () => { |
分析:
虽然这是一个很复杂的问题,但技巧其实只是对 当前行 和 当前列 的 _开头_ 以及 _结尾_ 的位置分别创建一个 临时变量 。这样,我们就可以按螺旋方向 _递增_ 遍历 起始行 和 起始列 并 _递减_ 遍历 结束行 和 结束列 直至方阵的中心。
因为该算法迭代地构建给定大小的 正方形 矩阵,它的运行时复杂度对时间和空间都是 _二次_ 型的。
代码:
See the Pen
Matrix Spiral by Thon Ly (@thonly)
on CodePen.
数据结构算法
既然数据结构式构建算法的 “砖瓦” ,那么非常值得深入探索常见的数据结构。
再一次,想要快速的高层次的分析,请查看:
Data Structures in JavaScript
For Frontend Software Engineers
medium.com
队列
给定两个 队列 作为输入,通过将它们“编织”在一起来创建一个 _新_ 队列。
1 | describe("Weaving with Queues", () => { |
分析:
队列 类至少需要有一个 入列(enqueue) 方法,一个 出列(dequeue) 方法,和一个 peek 方法。然后,我们使用 while 循环,该循环判断 peek 是否存在,如果存在,我们就让它执行 _出列_ ,然后 _入列_ 到我们的新 队列 中。
这个算法的时间和空间复杂度都是 O(n + m) 没因为我们需要迭代两个不同的集合,并且要存储它们。
代码:
See the Pen
Weaving with Queues by Thon Ly (@thonly)
on CodePen.
堆栈
使用两个 _堆栈_ 实现 Queue 类。
1 | describe("Queue from Stacks", () => { |
分析:
我们可以从一个初始化两个堆栈的 类构造函数 开始。因为在 _堆栈_ 中,最 _后_ 插入的记录会最 _先_ 被取出,我们需要循环到最后一条记录执行 “出列” 或者 “peek” 来模仿 _队列_ 的行为:最 _先_ 被插入的记录会最 _先_ 被取出。我们可以通过使用第二个堆栈来 _临时_ 保存第一个堆栈中所有的元素直到结束。在 “peek” 或者 “出列” 之后,我们只要把所有内容移回第一个堆栈即可。对于 “入列” 一个记录,我们可以简单的把它push到第一个堆栈即可。
虽然我们使用两个堆栈并且需要循环两次,但是该算法在时间和空间复杂度上仍然是渐近 _线性_ 的。
Though we use two stacks and need to loop twice, this algorithm is still asymptotically linear in time and space.
代码:
See the Pen
Queue from Stacks by Thon Ly (@thonly)
on CodePen.
链表
单向链表通常具有以下功能:
1 | describe("Linked List", () => { |
代码:
See the Pen
Linked List by Thon Ly (@thonly)
on CodePen.
挑战 #1: 中点
在不使用计数器的情况下,返回链表的 中间值
1 | describe("Midpoint of Linked List", () => { |
分析:
这里的技巧是同时进行 _两次_ 链表遍历,其中一次遍历的速度是另一次的 _两倍_。当快速的遍历到达结尾的时候,慢速的就到达了中点!
这个算法的时间复杂度是 _线性_ 的,空间复杂度是 _恒定_ 的。
代码:
See the Pen
Midpoint of Linked List by Thon Ly (@thonly)
on CodePen.
Challenge #2: 循环
在不保留节点引用的情况下,检查链表是否为 _循环_ 。
1 | describe("Circular Linked List", () => { |
分析:
很多的链表功能都基于链表有 _明确_ 的结束节点这个断言。因此,确保链表不是循环的这一点很重要。这里的技巧也是同时进行两次遍历,其中一次遍历的速度是另一次的两倍。如果链表是循环的,那么最终,较快的循环将与较慢的循环重合。这样我们就可以返回 true。否则,遍历会遇到结束点,我们就可以返回 false。
这个算法同样具有 _线性_ 时间复杂度和 _恒定_ 空间复杂度。
代码:
See the Pen
Circular Linked List by Thon Ly (@thonly)
on CodePen.
Challenge #3: From Tail
在不使用计数器的情况下,返回链表距离链表末端给定 步数 的节点的 _值_ 。
1 | describe("From Tail of Linked List", () => { |
分析:
这里的技巧和之前类似,我们同时遍历链表两次。不过,在这个问题中,速度“快”的遍历比速度“慢”的遍历 _早_ 给定步数 开始。然后,我们以相同的速度沿着链表向下走,直到更快的一个到达终点。这时,慢的遍历刚好到达距离结尾正确距离的位置。
这个算法同样具有 _线性_ 时间复杂度和 _恒定_ 空间复杂度。
代码:
See the Pen
From Tail of Linked List by Thon Ly (@thonly)
on CodePen.
树
树型结构通常具有以下功能:
1 | describe("Trees", () => { |
代码:
See the Pen
Trees by Thon Ly (@thonly)
on CodePen.
Challenge #1: 树的广度
对于给定的 树 ,返回每个级别的 _广度_ 。
1 | describe("Width of Tree Levels", () => { |
分析:
一个树可以通过 堆栈 对其所有的 _切片_ 进行 深度优先 的遍历,也可以通过 队列 的帮助对其所有的 _层级_ 进行 广度优先 的遍历。由于我们是想要计算每个级别的多有节点的个数,我们需要以 深度优先 的方式,借助 队列 对其进行 广度优先 的遍历。这里的技巧是往队列中插入一个特殊的 标记 来使我们知道当前的级别被遍历完成,所以我们就可以 _重置_ 计数器 给下一个级别使用。
这种方法具有 _线性_ 的时间和空间复杂度。尽管我们的 计数器 是一个数组,但是它的大小永远不会比线性更大。
代码:
See the Pen
Width of Tree Levels by Thon Ly (@thonly)
on CodePen.
Challenge #2: 树的高度
对于给定的 树 ,返回它的 _高度_ (树的最大层级)。
1 | describe("Height of Tree", () => { |
分析:
我们可以直接复用第一个挑战问题的逻辑。但是,在这个问题中,我们要在遇到 “reset”的时候增加我们的 计数器 。这两个逻辑几乎是相同的,所以这个算法也具有 _线性_ 的时间和空间复杂度。这里,我们的 计数器 只是一个整数,因此它的大小更可以忽略不计。
代码:
See the Pen
Height of Tree by Thon Ly (@thonly)
on CodePen.
图表
请等待后续补充! (谢谢)
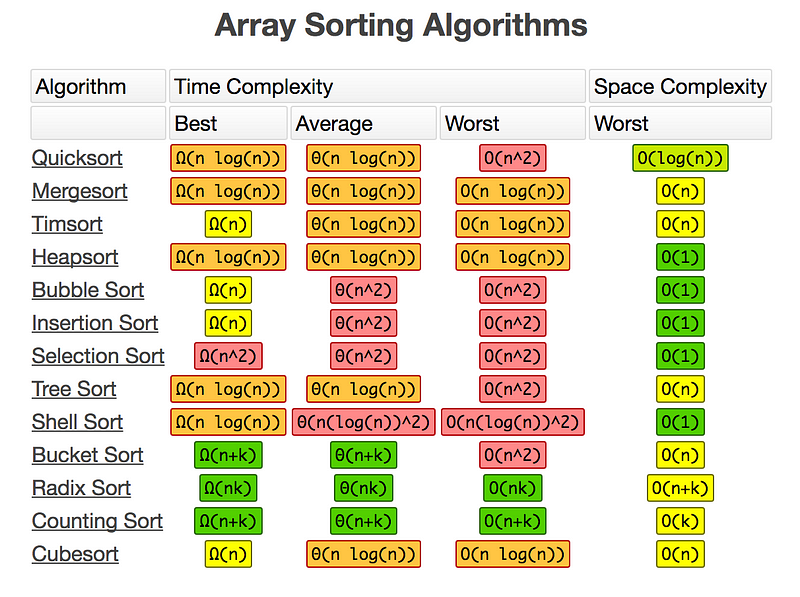
排序算法
我们可以使用许多种算法对数据集合进行排序。幸运的是,面试官只要求我们了解基础知识和第一原则。例如,最佳算法可以达到 _恒定_ 空间复杂度和 _线性_ 时间复杂度。本着这种精神,我们将按照困难度由简到难效率由低到高的顺序分析最受欢迎的几个算法。
冒泡排序
这个算法是最容易理解的,但效率是最差的。它将每一个元素和其他所有元素做 _比较_ , _交换_ 顺序,直到较大的元素 “冒泡” 到顶部。这种算法需要 _二次_ 型的时间和 _恒定_ 的空间。
See the Pen
Bubble Sort in JavaScript by Thon Ly (@thonly)
on CodePen.
插入排序
和冒泡排序一样,每一个元素都要与其他所有元素做比较。不同的是,这里的操作不是交换,而是 “拼接” 到正确的顺序中。事实上,它将保持重复项目的原始顺序。这种“贪婪”算法依然需要 _二次_ 型的时间和 _恒定_ 的空间。
See the Pen
Insertion Sort in JavaScript by Thon Ly (@thonly)
on CodePen.
选择排序
当循环遍历集合时,该算法查找并“选择”具有 最小值 的索引,并将起始元素与索引位置的元素交换。算法也是需要 _二次_ 型的时间和 _恒定_ 的空间。
See the Pen
Selection Sort in JavaScript by Thon Ly (@thonly)
on CodePen.
快速排序
该算法递归的选择一个元素作为 _轴_ ,迭代集合中其他元素,将所有更小的元素向左边推,将所有更大的元素向右边推,直到所有元素都被正确排序。该算法具有 _二次_ 时间复杂度和 _对数_ 空间复杂度,因此在实践中它通常是 最快度 的。因此,大多数编程语言内置都用该算法进行排序。
See the Pen
Quick Sort in JavaScript by Thon Ly (@thonly)
on CodePen.
归并排序
虽然这是效率最高的算法之一,但这种算法却难以理解。它需要一个 _递归_ 部分,将一个集合分成单个单元;并且需要一个 _迭代_ 部分,它将单个单元按正确的顺序重新组合在一起。这个算法需要 线性对数 时间和 _线性_ 空间。
See the Pen
Merge Sort in JavaScript by Thon Ly (@thonly)
on CodePen.
计数排序
如果我们用某种方式知道了 最大值 ,我们就可以用这个算法在 _线性_ 时间和空间里对集合排序!最大值让我们创建该大小的数组来 _计算_ 每个 索引值 出现的次数。然后,只需将所有具有 _非零_ 计数的索引位置的元素提取到结果数组中。通过对数组进行 恒定时间 查找,这个类似哈希的算法是最有效的算法。
See the Pen
Counting Sort in JavaScript by Thon Ly (@thonly)
on CodePen.
其他的排序算法
搜索算法
最糟糕的算法需要搜索集合中的每个项目,需要花费 O(n) 时间。如果某个集合已经被排序,那么每次迭代只需要一半的检查次数,花费 O(log n) 时间,这对于非常大的数据集来说是一个巨大的性能提升。
二分搜索
当一个集合被排序时,我们可以 _遍历_ 或 _递归_ 地检查我们的被检索值和中间项,丢弃一半我们想要的值不在的部分。事实上,我们的目标可以在 _对数_ 时间和 _恒定_ 空间情况中被找到。
See the Pen
Binary Search in JavaScript by Thon Ly (@thonly)
on CodePen.
二叉搜索树
另一种排序集合的方法是从中生成一个 二叉搜索树 (BST) 。对一个 BST 的搜索和二分搜索一样高效。以类似的方式,我们可以在每次迭代中丢弃一半我们知道不包含期望值的部分。事实上,另一种对集合进行排序的方法是按 _顺序_ 对这棵树进行 深度优先 遍历!
BST 的创建发生在 _线性_ 时间和空间中,但是搜索它需要 _对数_ 时间和 _恒定_ 空间。
See the Pen
Binary Search Tree by Thon Ly (@thonly)
on CodePen.
要验证二叉树是否为BST,我们可以递归检查每个左子项是否总小于根(最大可能),并且每个右子项总大于 每个根 上的根(最小可能)。这种歌方法需要 _线性_ 时间和 _恒定_ 空间。
See the Pen
Validate a Binary Search Tree by Thon Ly (@thonly)
on CodePen.
总结
在现代Web开发中,函数 是Web体验的核心。数据结构 被函数接受和返回,而 算法 则决定了内部的机制。算法的数据结构的数量级由 空间复杂度 描述,计算次数的数量级由 时间复杂度 描述。在实践中,运行时复杂性表示为 Big-O 符号,可帮助工程师比较所有可能的解决方案。最有效的运行时是 _恒定_ 时间,不依赖于出入值的大小;最低效的方法需要运算 _指数_ 时间和空间。真正掌握算法和数据结构是指可以同时 _线性_ 和 _系统_ 的推理。
理论上说,每一个问题都具有 迭代 和 递归 的解决方案。迭代算法是从底部开始 _动态_ 的接近解决方案。递归算法是从顶部开始分解 重复的子问题 。通常,递归方案更直观且更易于实现,但是迭代方案更容易理解,且对内存需求更小。通过 一流的函数 和 控制流 结构,JavaScript 天然支持这两种方案。通常来说,为了达到更好的性能会牺牲一些空间效率,或者需要牺牲性能来减少内存消耗。正确的平衡两者,需要根据实际上下为和环境来决定。值得庆幸的是,大多数面书馆都更关注 计算推理过程 而不是结果。
为了给你的面试官留下深刻的印象,要尽量寻找机会利用 架构设计 和 设计模式 来提升 可复用性 和 可维护性 。如果你正在寻找一个资深职位,对基础知识和第一原则的掌握与系统级设计的经验同样重要。不过,最好的公司也会评估 文化契合 度。因为没有人是完美的,所以合适的团队是必不可少的。更重要的是,这世上的一些事是不可能凭一己之力达到的。大家共同创造的东西往往是最令人满意和最有意义的。